Doctors Learn to Decode Brain Signals, Giving a Voice to the Voiceless
"The speech centers are still working, but they can’t get the words out."
Most humans can speak by the time they’re 2 years old, and most of us probably take this ability for granted. It’s how we interact with friends, strangers, and enemies alike.
For people who have suffered a stroke or who live with amyotrophic lateral sclerosis (ALS), the inability to speak can leave them feeling trapped inside a body that’s unwilling to cooperate. But in recent years, scientists have made strides in the development of brain-computer interfaces that can translate brain signals into computerized speech.
A team at the University of California, San Francisco suggests that brain-computer interfaces — also known as neuroprostheses — are within reach.
On Wednesday, researchers at the UCSF Department of Neurological Surgery showed evidence that they could decode neuronal signals into human speech, which suggests that as long as most of a person’s brain is intact, they could one day be given the ability to communicate — even without use of their mouth.
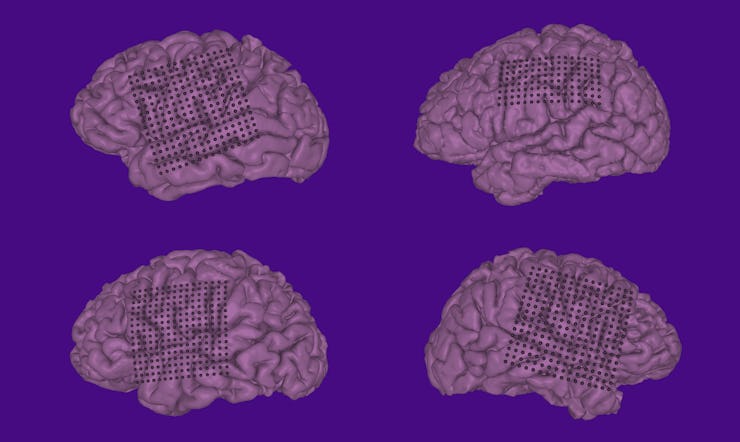
Researchers placed sensors directly on the cortex of a person’s brain, and the recorded activity associated with movements of the jaw, tongue, and lips translated those motions into synthesized human speech.
The team described its findings in a paper published in the journal Nature.
Neurosurgeon Edward Chang, M.D., the principal investigator of the lab behind the research, says the new study proves that technology can help patients recover the ability to speak.
“It’s been a long-standing goal of our lab to create technologies to restore communication for patients with severe speech disability, either from neurological conditions such as stroke or other forms of paralysis, or conditions that result in the inability to speak from even injuries to the vocal tract or cancer,” he told reporters Tuesday.
“We combined state-of-the-art methods from neuroscience, deep learning, and linguistics to synthesize natural sounding speech from brain activity of research participants that did not have any speech impairment in order to demonstrate this proof of principle,” he said.
To perform the experiments involved in this study, Chang and his co-authors, Ph.D. student Josh Chartier and postdoc Gopala Anumanchipalli, Ph.D., recruited five patients who were already undergoing surgery for epilepsy that had not responded to other forms of treatment. As part of their epilepsy treatment, they had large electrode arrays implanted onto the surface of their brains — a common technique doctors use for monitoring epileptic patients’ brain activity when they have had trouble pinning down the cause of frequent seizures.
In this case, though, the sensor arrays fulfilled an additional purpose: They tracked the neuronal signals from the patients’ brains, allowing Chang and his team to develop a map of motions that the vocal tract makes when people are speaking. Placed over the sensorimotor cortex (the part of the brain that covers sensory and motor functions), the sensors recorded the signals created when the volunteers spoke out loud, and when they mouthed words without making sounds.
The volunteers read a variety of materials aloud to give the researchers material to build a library of how certain speech patterns look in the brain. For instance, one of the test subjects read aloud passages from Sleeping Beauty, Frog Prince, Hare and the Tortoise, The Princess and the Pea, and Alice in Wonderland. Another participant was asked to recite written sentences describing scenes and then freely describe the scenes in their own words. This part of the experiment helped Chang’s team determine what the brain is doing when the mouth is speaking.
With this huge collection of data, then, they reconstructed speech through a computer. While the experiment didn’t take place in real time — it took them about a year to analyze the brain signal data and match it up to mouth sounds — the video below shows that it did achieve a remarkable degree of success in recreating words from the brain signals that occurred when participants mouthed words.
While these results are promising, they do have limitations. For instance, this technology wouldn’t apply to all individuals who have lost the ability to speak. Chang told reporters that it would only work for people whose portion of the motor cortex associated with the vocal tract is intact. So, at least at this point, any neuroprosthesis that is derived from this research would apply to people who had brain stem strokes or ALS due to the unique nature of their conditions.
“The speech centers are still working, but they can’t get the words out,” Chang says.
Another barrier to developing neuroprosthetic devices is that the sensor arrays used in this study are rather invasive, requiring surgery to implant.
Unfortunately, Chang isn’t aware of any currently available technology that could read brain signals precisely enough from outside the skull to translate them into speech.
“That could be potentially really exciting in the future if it doesn’t require a surgery to do this kind of thing,” he said.
Despite the fact that neuroprosthetic headbands aren’t yet a reality, others in the field are impressed by the progress.
Nima Mesgarani, Ph.D., is an associate professor of neural acoustic processing at Columbia University. He wasn’t involved in this study, but as Inverse has previously reported, his work has also focused on brain-computer interfaces that could one day help patients recover the ability to speak.
Mesgarani tells Inverse that the new Nature study represents a big step in the development of speech neuroprosthesis.
“One of the main barriers for such devices has been the low intelligibility of the synthesized sound,” he says. “Using the latest advances in machine learning methods and speech synthesis technologies, this study and ours show a significant improvement in the intelligibility of the decoded speech.”
He notes that the main difference between his team’s research and this latest paper is that his team focused on brain activity in the sensory cortex, which is involved in our perception of speech, while this one focuses on the motor cortex, which is where we produce speech.
“What approach will ultimately prove better for decoding the imagined speech condition remains to be seen,” he says, “but it is likely that a hybrid of the two may be the best.”
Abstract:
Technology that translates neural activity into speech would be transformative for people who are unable to communicate as a result of neurological impairments. Decoding speech from neural activity is challenging because speaking requires very precise and rapid multi-dimensional control of vocal tract articulators. Here we designed a neural decoder that explicitly leverages kinematic and sound representations encoded in human cortical activity to synthesize audible speech. Recurrent neural networks first decoded directly recorded cortical activity into representations of articulatory movement, and then transformed these representations into speech acoustics. In closed vocabulary tests, listeners could readily identify and transcribe speech synthesized from cortical activity. Intermediate articulatory dynamics enhanced performance even with limited data. Decoded articulatory representations were highly conserved across speakers, enabling a component of the decoder to be transferrable across participants. Furthermore, the decoder could synthesize speech when a participant silently mimed sentences. These findings advance the clinical viability of using speech neuroprosthetic technology to restore spoken communication.
